



Nishika AI News Letter - Issue #74

OpenAIから新AIモデル「o1」が発表されました。個人的・当社的にはLLMに結構複雑なタスクをやらせているので、内省により複雑なタスクを解く能力が高まったo1-previewにはかなり期待しているのですが、一方でほとんどのユーザーの期待値はもっと高いところにあるだろうなと感じますし、2Bのユースケースでマネタイズするには違った観点の進化が必要だと感じます。
Promotion

SecureMemoCloudは、世界最高水準の精度96.2%の音声認識AIを搭載した会議録作成支援サービスです。
評価用に作成された綺麗な読み上げ音声ではなく、リアルなビジネス会議音声について他社の追随を許さない高精度を誇るAIモデル「shirushi」を搭載している点が最大の特徴です。さらに、音声認識AIと生成AIを組み合わせた専門用語・社内用語の認識機能を備えており、圧倒的な認識性能を誇ります。
将来は、文字起こし結果をもとに会議アシスタントとしてあなたをサポートする生成AIの搭載を目指しています。

SecureMemoは、世界最高水準の精度96.2%の音声認識AIを搭載しつつ、オフライン環境で処理が完結するAI文字起こしソフトウェアです。
「精度の圧倒的な高さ」「オフライン完結」の2つを両立しているサービスは他になく、警察・医療機関・民間企業の経営企画/IR/人事部門様といった皆様にお使いいただいています。
評価用に作成された綺麗な読み上げ音声ではなく、リアルなビジネス会議音声について他社の追随を許さない高精度を誇るAIモデル「shirushi」を搭載している点が最大の特徴です。さらに、独自開発した、声紋登録不要で完全自動の話者特定AIも搭載しています。
Application
OpenAI o1とは?6つの特徴や利用制限、GPT-4oとの違いを解説
OpenAIから新AIモデル「o1」が発表されました。能力は博士課程並みなどと報道されていますが、気になるのは「ビジネスシーンで役にたつのか」かと思います。
今回発表されたAIモデルは「o1-preview」と「o1-mini」の2つがあり、一見してgpt-4oとgpt-4o-miniのように廉価版かと見えますが、実際には得意領域が異なるものです(なので、ネーミングが誤解を招きもったいないなと感じます)。既存モデルであるGPT-4oの方が優れているユースケースもあり、本記事中の下表がよくまとめられています。

o1-previewをよく触っていますが、以下例のように、GPTが自分の思考を内省するような仕組みになっています。その分少し推論時間がかかりますが、複雑なタスクを行わせたい場合に非常に有効に動作しているように感じます。

一方で、以下のようなコード作成に関する回答はGPTシリーズにはできず、Claudeの強みもあります。「現時点では」ユースケースによってLLMを使い分ける必要があります。

Google、AIの“幻覚”に対処する「DataGemma」をオープンモデルでリリース
GPT o1では自分の思考を内省するロジックがデフォルトで入りましたが、例えばリサーチ用途では、RIG(モデルの元の生成とData Commonsに保存されている関連統計を比較)もデフォルト実装されていてほしいところです。
生成AIプロジェクトの「30%が中止」に? iPhone16が大注目でも「AIバブル崩壊」へ…
法人ユーザーがAI支出に絡んだ投資収益率(ROI)に満足することが決定的に重要
とありますがその通りで、生成AIが2Cでマネタイズできるハードルと2Bとでは相当な違いがあります。
正直、2Bでマネタイズできるかという意味では、GPT-4oからo1への進化程度ではさして影響がない、というのが実態な気がしています。
企業内データを如何にLLMが学習できる形に整えるかなど、別の観点の進化が必要です。
Technology
RAGにベクトルDBは必要ない!DBも不要で運用めちゃ楽な RAG Chatbot を作った話
RAGでは半ばデファクトスタンダード化しているベクトルDBを使わずに、クエリに意味的に近いドキュメントを取得する手法の提案。
RAGではベクトルDBの活用が前提となるケースが多いが、ドキュメントの新規追加や更新時、ベクトルを都度作成する必要があるなど、常にDBを最新の状態に保つ点で手間がある。
そもそもベクトルDBを活用するモチベーションは、クエリに意味的に近いドキュメントを取得すること。
LLMを使って、クエリに含まれるキーワードを類義語で多重化する手法でも、同様の狙いが達成でき、かつベクトルDBを必要としないのではないか、というアイデア。

色々メリットはありますが、記事で言及されているベクトルDBのメンテナンスが不要となる点以上に、どのような検索がなされたか、ベクトルDBのようにブラックボックス化されず、チューニングしやすい点が大きなメリットであると感じます。
ベクトルDBで実現できる高速な検索が失われるデメリットもありますが、試す価値ありと感じます。
一方で、LLMであっても専門用語に対する類義語が出せないことは依然として課題です。これについては、次に紹介するナレッジRAGが有用な可能性があります。
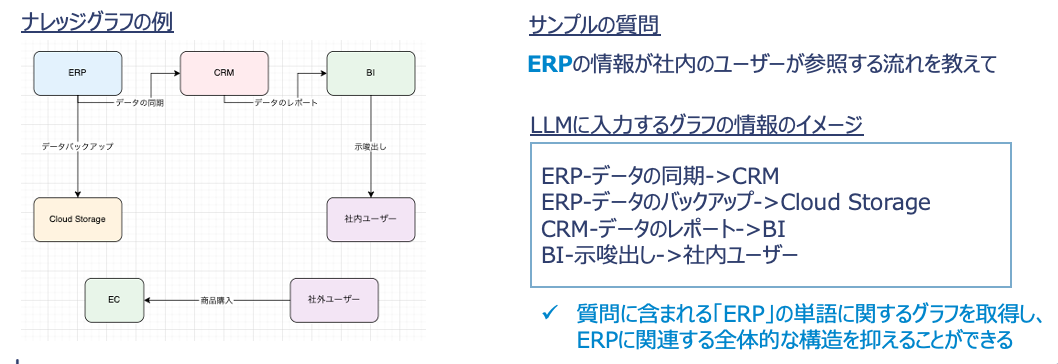
RAGやナレッジ検索アプローチの進化 生成AIによる情報検索精度が大幅アップ
ベクトルDBは、類義語を類似のベクトルとして置き換えることで検索により類義語を含め引っ掛けることができるようになる点が利点。
一方で、学習データに含まれない専門用語についてはベクトル化できず、当然類義性についても理解できない点が課題でした。
本記事は、専門用語を含むドキュメントについてLLMを使ってナレッジグラフを作成し、いざ質問する際にナレッジグラフを併せて入力することで、専門用語の知識を「注入」することができるという提案です。
Editor Picks
「進化的モデルマージ」を提唱し、LLMと同等の精度を小規模モデルの集合で実現することを目指すSakana AIですが、シリーズAとして合計300億円の資金調達を完了したとのこと。日本のメガバンクが軒並み出資。
Sakana AIの可能性については全く否定しないのですが、日本のメガバンク・大企業が軒並み出資しているというのが、ちょっと「ダサい」と思ってしまったのは私だけでしょうか・・・。どの程度、自社独自の分析で出資を決めたのかどうか。横並びでエイヤと決めた出資でないことを願いたいところです。