



GPTモデル(即時応答型)は一区切り。 Nishika AI News Letter - Issue #84

o1 proもDeep Researchも最早手放せない今日この頃。今はやりたいことに応じて利用するサービスを使い分けている状態ですが、即時応答型のモデルとして最後のリリースとなったGPT-4.5の次のモデルは、即時応答と長時間思考を使い分けるモデルとなるとのこと。ただ一つの入力窓口に集約される日も近そうです。
Promotion

「業務で生成AIを使いたいがパブリックな環境でインターネット通信されるのが不安」というニーズのある企業様向けに、自社専用のオフライン生成AI・RAGアプリケーション導入を支援しています。
プライベートな環境で社内Qに回答してくれる生成AI「AIコンシェルジュ」
自社専用生成AI「クラフト生成AI」
AI議事録ツールSecureMemoで培った生成AI開発の知見、および自然言語検索・前処理の技術を組み合わせた、高精度な体験を提供します。

SecureMemoは、世界最高水準の精度96.2%の音声認識AIを搭載し、生成AIによる要約に至るまでをオフライン環境で完結するAI文字起こしソフトウェアです。
「オフライン×世界最高水準の音声認識」「オフライン×生成AI要約」の2つを両立しているソフトウェアとして、現在日本で唯一無二であると考えています。
警察・医療機関・製造業・金融機関・大学等へ導入実績がございます。

SecureMemoCloudは、世界最高水準の精度96.2%の音声認識AIを搭載した会議録作成支援サービスです。
評価用に作成された綺麗な読み上げ音声ではなく、リアルなビジネス会議音声について他社の追随を許さない高精度を誇るAIモデル「shirushi」を搭載している点が最大の特徴です。
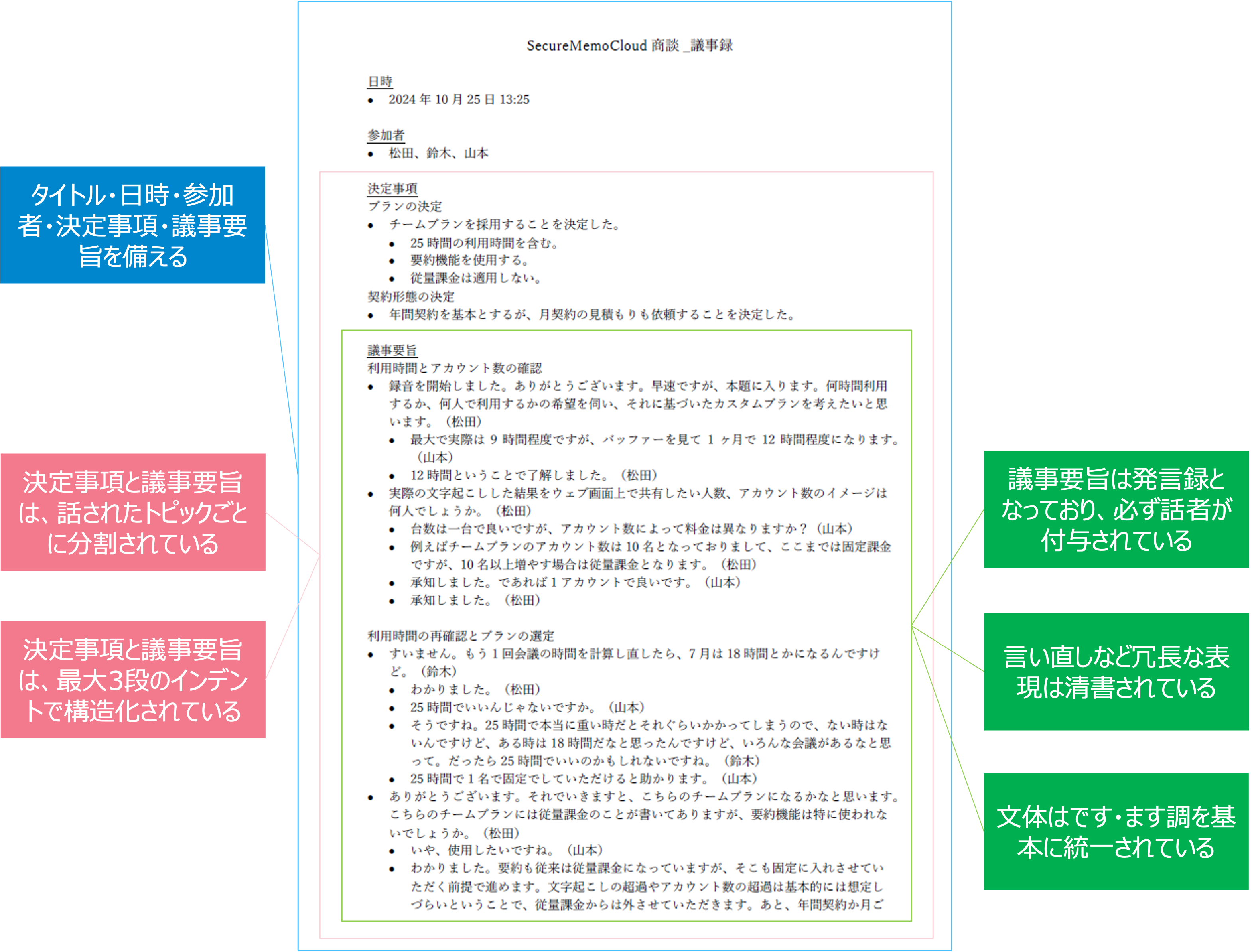
もう1つの特徴は、ほぼ完成版の議事録「ほぼ完議事録」機能。
日時・参加者・決定事項・議事要旨を備えつつ、トピック分割やインデントを活用した構造化を行い、さらに話者の付与・清書・文体の統一などを全てAIが行なった、業界で他に類を見ない機能です。
Application
2月初旬にChatGPTに実装された、公開情報を多方面でリサーチしその結果をレポートしてくれる機能。
o1 proと併せて個人的に毎日のように利用していて、明らかに業務効率向上に役立っている。
依頼を投げるとそのまま対応するのではなく、要件を明確にして欲しいポイントを聞き返してくるのがGood。まさに仕事のできる人の動き方。

使い方は無数にあるが、個人的にDeep Researchがないとできなかったなと思うのは日英以外の言語ソースの情報調査。LLMは多くの言語を解釈できるので、指示は日本語でも情報源は多言語でレポートをまとめてくれるのは今までにできなかった。
また、単にこれまで提供していたLLMモデルにWeb検索をさせているのではなく、Web検索結果をどう処理するかトレーニングしたモデルを使用しているとのこと。同名の「Deep Research」という機能はGeminiやPerplexityからも出されていてややこしいが、モデルトレーニングの違いもあってか、リサーチの深さはChatGPTが数段上。
(他社に比べれば)LLMの新モデルのリリースが止まっていたAnthropicがClaude-3.7をリリース。他社と同様長時間思考モデルも搭載された。
以前からClaudeの強みであったコーディング能力が他社の最新モデルに比して上回る。

また、資料作成が可能であることも話題となっている。
実際に使ってみると、製品紹介資料に使えるレベルではない(明らかにAIが作成していて、手抜きだなと感じられるレベル)が、高速に報告を求められる用途であれば十分利用できる。
即時応答するモデルとしては最後のリリースと明言されているGPT-4.5がリリース。
タスクを解く能力が上がったのではなく、人間らしい回答をするようになったのが強みとのこと。
しかし、API費用はばか高い。gpt-4oが1M 入力トークンあたり2.5USDに対してgpt-4.5は75USD。
性能の向上が渋い中でこの価格設定は「使ってほしくない」意図を感じる。多分にマーケティング目的でリリースされた?
また、Sam Altman氏のX投稿でロードマップも言及されている。今後は即時応答と長時間思考を使い分けるモデルとして統合されていく。
OPENAI ROADMAP UPDATE FOR GPT-4.5 and GPT-5:
We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings.
We want AI to “just work” for you; we realize how complicated our model and product offerings have gotten.
We hate the model picker as much as you do and want to return to magic unified intelligence.
We will next ship GPT-4.5, the model we called Orion internally, as our last non-chain-of-thought model.
After that, a top goal for us is to unify o-series models and GPT-series models by creating systems that can use all our tools, know when to think for a long time or not, and generally be useful for a very wide range of tasks.
In both ChatGPT and our API, we will release GPT-5 as a system that integrates a lot of our technology, including o3. We will no longer ship o3 as a standalone model.
The free tier of ChatGPT will get unlimited chat access to GPT-5 at the standard intelligence setting (!!), subject to abuse thresholds.
Plus subscribers will be able to run GPT-5 at a higher level of intelligence, and Pro subscribers will be able to run GPT-5 at an even higher level of intelligence. These models will incorporate voice, canvas, search, deep research, and more.OpenAIのoシリーズ、Reasoningモデルのベストプラクティスを公式に公開。「段階的に考えて」などの指示はReasoningモデルの性能向上にはつながらない場合が多いなど。
markdown形式で出力が欲しい場合に「Formatting re-enabled」のキーワードを入れる、というのは如何にもハックっぽく、それを公式が推奨するのもなかなか面白い。
Technology
LLMの弱点だった「長期記憶」の克服へ、Googleの注目論文Titansを読み解く
長期記憶はLLMの課題であり、入力できる情報量に関わるコンテキストウィンドウを拡張するには計算量が二乗で増大する。
この問題に取り組むべく、現在LLMで採用されているTransformerではないアーキテクチャー「Titans」をGoogleが開発している。Titansでは驚きを記憶する仕組みを取り入れており、イベントが予想に反する場合(驚くべき場合)、より記憶に残るという考え方に基づいている。needle in haystackタスク(長い文章の中から特定の情報を取り出せるかを評価するタスク)ではTransformerアーキテクチャを上回っている。コードの公開も予定されている。
Editor Picks
Claudeの400万件以上の会話を分析。どのような職種・業務で利用されているか分析された。アンケートなどではなく、実態に基づいた大規模解析は初めてと思われる。
AIの利用はソフトウェア開発に集中しており、全体の37.2%を占める。(米国の労働者数の割合としては3.4%である)
作業の75%にAIを利用しているのが全体の4%の職業、作業の25%にAIを利用しているのが全体の36%の職業。
低賃金の職業と非常に高賃金の職業の両方でAIの利用率は非常に低い。(理美容や産科医が例に挙げられている)
元々ソフトウェアプログラミングでの利用が多いClaudeの結果としてみる必要はある。
 despite representing only 3.4% of workers. Office and administrative support has the highest workforce percentage (12.2%) with 7.9% AI usage. Other notable disparities include Arts and Media (10.3% AI usage vs 1.4% workers) and Transportation (0.3% AI usage vs 9.1% workers). Farming shows the lowest representation in both categories (0.1% AI usage, 0.3% workers).")